The complexities of intelligence (late night ramblings of a madman)
I’m sure I’m not the only one who knows of someone who, as a young child, had a dog. They liked dogs, so they learned dogs. Dogs have four legs, and they stand on them. One day, it became apparent that everything standing on four legs was a dog. A cat was a dog, a cow was a dog, a horse was a dog… you know the story.
Recognizing things is what we do – from the moment we are born we use every sense we have to make sense of the world – and it’s not just a people thing – even a plant must follow the sun. Then we bring in one of these computer things to make our lives “easier” and discover that simplifying even the most mundane tasks requires quite a lot of understanding of how we did it manually in the first place.
I took a geometry course in my college days, probably one of the best courses I’ve ever taken with one of the most driven classmates I’ve had the pleasure of knowing. We would joke about the pedantic nature of our learning objectives, but it really was that course’s brilliance. We started with the definition of a point and built from there. Then to line segments and lines, definitions and proofs of parallel based on theorems we never thought we would need to know. After weeks, we finally discovered a shape: the triangle. We could barely define it, but we could recognize it.
Is that how we first recognized a triangle when our eyes first opened? No, probably not, but when working with computers, how we define the environment we are investigating is how we must program our recognition, much like in that class, pencil and paper were our senses. Something as seemingly simple as word searching can become quite complicated in short order.
Level 1
Consider just finding the word ‘fox’ in the text below:
The quick brown fox jumps over the lazy dog.
Easy, right? Matching character for character. How about now?
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
Only slightly harder. Simple ASCII math can handle the translation for you. Again:
7h3 qu1ck br0wn f0x jump5 0v3r 7h3 l4zy d06.
Uh oh. Well, you could write a l33t speak decoder just in case… Again:
τнε φμιςκ βяοωη ƒοχ jμмρs οvεя τнε ℓαζλ δοg.
Had enough? It’s all Greek to me, but I’m sure you could still read it.
Fine.
Next level – Comparison.
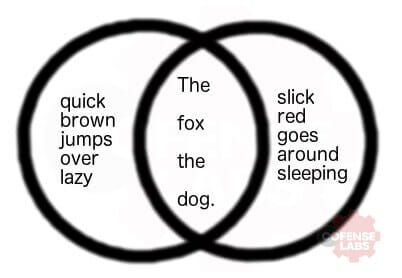
What are the similarities in the following sentences: “The quick brown fox jumps over the lazy dog.” and “The slick red fox goes around the sleeping dog.”
I know it sounds pedantic, but define similarities, right?? Do we want to know if one sentence is longer than the other? If the mean of the ascii values is greater or less than the other? Maybe words in common vs words not in common like some kind of Venn diagram result, that sounds simple enough – although the question remains: is a sentence more or less like another based simply on word appearance, or the unique word set? Let me list to you some ways a simple comparison can be interpreted with some mixed in pseudocode –
a = “The quick brown fox jumps over the lazy dog.”
b = “The slick red fox goes around the sleeping dog.”
len(b)>len(a) ## sentence b is longer than sentence a.
mean_a = sum()/len(a)
mean_b = sum()/len(b)
mean_a>mean_b ## sentence a has a higher numerical mean.
Here’s that Venn diagram we were looking for
Let’s throw in some bioinformatics with a nice dot plot showing exact substring alignment. Don’t forget about the possible complexities that could be involved with not-exact matching.

Level C – Categorization
So now we want to group things together. We have some methods of comparison; do we just want exact matches? Maybe we should set a threshold in which meeting that threshold of similarity means they are similar enough to group together? It’s easy if we’re sorting candies here, put the red ones with red ones, blue ones with blue ones, etc. It’s pretty simple if we’re sticking with finite things like words. The Venn diagram above shows pretty good connections with four words, is that enough? How about the dot plot? It handles substring matching and matching on spaces and everything. There’s already a threshold of 3 characters to equate sequence alignment. You could add them all together and divide by the average length of the two sentences being compared, right? Could it be a problem if the sum of sequence alignment lengths is greater than the average? Sure, but it could be capped at 100% maybe. But what does that say about the match, is it really that good? Words that rhyme would have a pretty good sequence alignment score, but that doesn’t mean they have anything to do with one another.
Why am I droning on and on about this?
Well these are some of the baby steps that need to be considered when attempting to classify things like email algorithmically. People can be really, really good at it, it’s not just intuition, there is practice involved, trial, error, and a large amount of collaboration leading to consensus. This is one of the reasons that we are “uniting humanity against phishing” instead of relying solely on rulesets and definitions. Of course they can help, and of course they can make life much easier for those doing analysis, but without constant upkeep of new comparisons, definitions, and techniques for recognition, these cutting edge systems can go dull in short order.
All third-party trademarks referenced by Cofense whether in logo form, name form or product form, or otherwise, remain the property of their respective holders, and use of these trademarks in no way indicates any relationship between Cofense and the holders of the trademarks.


