After researching everything you want to know about domain blacklists, Jonathan Spring and Leigh Metcalf – two members of the technical staff at the CERT Division of Carnegie Mellon University’s Software Engineering Institute – performed an additional analysis and case study on the Domain Blacklist Ecosystem.
Their research supports a hypothesis regarding how the difference in the threat indicators available from a range of different sources is related to sensor vantage and detection strategy. To facilitate this, they required a source of intelligence that varied the detection strategy without changing the sensor vantage.
University research continues to play an important role in how we develop and deliver our threat intelligence services today. As such, we are very pleased to assist Jonathan and Leigh in their on-going analysis of the cyber threat landscape and the intelligence being leveraged to protect networks, employees, and data from threat actors.
An indicator detection process enables us to specify whether the network touchpoint is a mail sender, an initial infection vector, or a location derived during malware runtime. Our intelligence feed further specifies how IP addresses, domains, and URLs are being used in support of an attack. This provides insight into where overlap is occurring and if components are being used for multiple purposes, both of which were key aspects of the CERT analysis.
PhishMe’s Indicators
Compared to 26 domain-based lists and 53 IP-address-based lists provided by other threat intelligence providers, we reported unique threat indicators 50% – 77% of the time.
Payload server: 77% unique
C2 server: 59% unique
Infection URL: 58% unique
Spam sender: 50% unique
Table 1: Sub-list intersections with all other indicator sources. (From CERT blog)
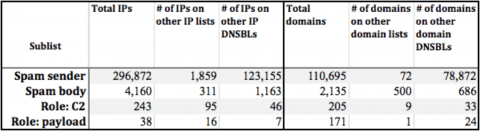
These data demonstrate that our threat intelligence exposes significant unique indicators while adding context and validity to duplicate indicators being collected from other sources. If a threat provider’s data have little overlap with 79 other blacklists, one should consider the applicability of those data. Are they stale? Are they regional? Do they apply to my business? Conversely, if a threat provider offered nothing unique, it would have little additive value. We believe this analysis demonstrates the ideal blend of confirmation and uniqueness of our data.
Bad Intelligence Is Costly Intelligence
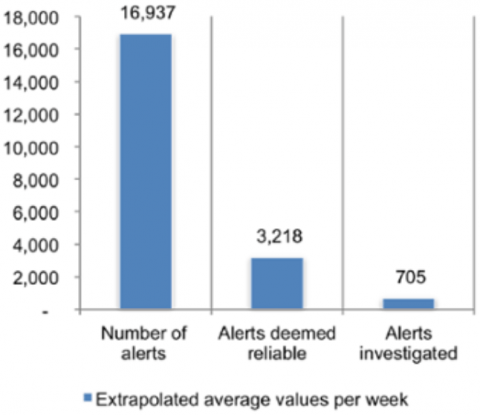
Based on the premise that more is better, there was a rush over the past few years to collect as much threat intelligence as possible. However, it’s costly to analyze data on the way into security appliances to ensure that unreliable indicators are removed. It is even more expensive to filter and chase false positives triggered as a result of mediocre data sets. Choosing reliable providers that facilitate an effective response is therefore critical. The Ponemon Institute recently calculated that it costs the companies they surveyed $1.2M per year in time wasted chasing false positives. The Ponemon chart below shows that companies don’t even respond to most of the alerts that are generated – information overload is another problem altogether.
Chart 1: 2015 Ponemon Institute Cost of Data Breach Study
Data Quality
We filtered out benign domains, IP Addresses, and URLs during our malware and phishing analysis. This is one reason why you see less overlap between our intelligence and that of other sources. The high-signal aspect of our intelligence service makes it a viable source for automated rules designed for blocking network communication and escalating events. Furthermore, while the spam sender’s IP is useful for forensics, we don’t recommend automating actions using this indicator.
We use the MITRE STIX Campaign definition as the primary way of publishing threat intelligence in machine-readable format, including impact scores for each element. The full campaign file contains a rich set of vetted indicators collected using a combination of proprietary analytics and malware analyses. Portions of threat intelligence service are published in formats optimized for SIEMs and other security appliances. We also provide the intelligence in JSON format for data scientists and the data hungry among us.
From Research to Production
The CERT analysis required a multi-faceted detection strategy with structured reporting of malware campaigns. This same approach is critical to deriving threat intelligence that is reliable, consumable, and contextual – all requirements for InfoSec teams relying on more automation to keep up with increasing volumes of incidents and alerts. It’s much easier to respond when you know what caused an alert or what’s at the other end of a network request. Similarly, finding value in threat intelligence is much easier after finding the right source of threat intelligence.


